library(tidyverse)
library(car)
library(paletteer)
library(kableExtra)Introduction
In the previous post, I introduced two fundamental concepts to analyze categorical data: cross-table and the chi-squared test.
This post goes one step further by offering two tools for data analysis, which will work with numeric and categorical data: summary statistics and the independent samples t-test.
As part of descriptive statistics, summary statistics can provide valuable insights into data sets. It may include essential metrics such as the total number of values, the mean value, and the standard deviation. These statistics provide a clear picture of data trends and distribution, aiding in the interpretation of data patterns. On the other hand, the independent-samples t-test (part of inferential statistics) is employed to compare means between two distinct groups. It helps us investigate whether these two groups differ significantly in a particular dimension. When used together, these tools can reveal intriguing patterns and relationships within data.
The rest of the post will guide you through the utilization of summary statistics and the independent-samples t-test for insightful data analysis.
Introducing two distinct tools for data analysis with numeric and categorical data using R
- Summary statistics
- Independent samples t-test
Case study
- Focused on diversity and inclusion (D&I)
- Sourced from the book Predictive HR Analytics : Mastering the HR Metric
- With data available here
Problem Statement
A hypothetical company aims to employ data analytics to tackle a significant people problem: employee diversity. It recognizes that:
Commercial Perspective : a more diverse workforce can provide a competitive advantage by enhancing the organization’s understanding of its customers, consequently improving overall performance.
People Perspective : the organization gains access to a broader candidate pool, increases employee engagement, and elevates retention rates.
Analysis question
How does the distribution of Black, Asian, or Minority Ethnic (BAME) employees vary across different professions?
Data Preparation and Exploration
Load packages
Data set
For this case study I used a data set available here.
The company, a hypothetical organization, comprises 29,976 employees in two functional areas across the UK, and these employees are organized into 928 teams.
The data set contains 30 variables.
Data type (in the data set): numeric for all variables.
diversity <- read_csv("diversity2.csv")
skimr::skim(diversity)| Name | diversity |
| Number of rows | 928 |
| Number of columns | 30 |
| _______________________ | |
| Column type frequency: | |
| numeric | 30 |
| ________________________ | |
| Group variables | None |
Variable type: numeric
| skim_variable | n_missing | complete_rate | mean | sd | p0 | p25 | p50 | p75 | p100 | hist |
|---|---|---|---|---|---|---|---|---|---|---|
| DepartmentGroupNumber | 0 | 1.00 | 470.62 | 270.05 | 1.00 | 237.75 | 470.50 | 704.25 | 937.00 | ▇▇▇▇▇ |
| GroupSize | 1 | 1.00 | 32.30 | 16.24 | 10.00 | 18.00 | 28.00 | 45.00 | 71.00 | ▇▆▃▃▂ |
| PercentMale | 1 | 1.00 | 58.95 | 22.27 | 1.00 | 45.00 | 65.00 | 67.00 | 100.00 | ▁▃▅▇▃ |
| BAME | 182 | 0.80 | 0.12 | 0.11 | 0.00 | 0.03 | 0.09 | 0.20 | 0.45 | ▇▃▂▂▁ |
| NumberTeamLeads | 1 | 1.00 | 4.61 | 2.33 | 1.00 | 3.00 | 4.00 | 6.00 | 10.00 | ▅▇▅▃▂ |
| NumberFeMaleTeamLeads | 20 | 0.98 | 0.68 | 1.06 | 0.00 | 0.00 | 0.00 | 1.00 | 8.00 | ▇▂▁▁▁ |
| Location | 0 | 1.00 | 2.12 | 0.85 | 1.00 | 1.00 | 2.00 | 3.00 | 3.00 | ▆▁▅▁▇ |
| LondonorNot | 0 | 1.00 | 1.43 | 0.49 | 1.00 | 1.00 | 1.00 | 2.00 | 2.00 | ▇▁▁▁▆ |
| Function | 1 | 1.00 | 1.46 | 0.50 | 1.00 | 1.00 | 1.00 | 2.00 | 2.00 | ▇▁▁▁▇ |
| EMPsurvEngage_1 | 1 | 1.00 | 88.14 | 11.24 | 22.00 | 83.00 | 91.00 | 96.00 | 100.00 | ▁▁▁▂▇ |
| EMPsurvEngage_2 | 1 | 1.00 | 87.50 | 10.88 | 45.00 | 82.00 | 90.00 | 96.00 | 100.00 | ▁▁▂▅▇ |
| EMPsurvEngage_3 | 1 | 1.00 | 85.63 | 13.43 | 33.00 | 80.00 | 89.00 | 95.00 | 100.00 | ▁▁▁▃▇ |
| EMPsurvEngage_4 | 1 | 1.00 | 75.98 | 13.77 | 29.00 | 68.00 | 78.00 | 86.00 | 100.00 | ▁▂▅▇▅ |
| EMPsurvEngage_5 | 1 | 1.00 | 91.49 | 8.80 | 44.00 | 88.00 | 93.00 | 98.00 | 100.00 | ▁▁▁▂▇ |
| EMPsurvEngage_6 | 1 | 1.00 | 68.60 | 15.96 | 11.00 | 58.00 | 69.00 | 80.00 | 100.00 | ▁▂▆▇▃ |
| EMPsurvEngage_7 | 1 | 1.00 | 89.98 | 9.82 | 25.00 | 86.00 | 92.00 | 97.00 | 100.00 | ▁▁▁▂▇ |
| EMPsurvEngage_8 | 1 | 1.00 | 66.75 | 15.31 | 0.00 | 57.00 | 68.00 | 78.00 | 100.00 | ▁▁▅▇▃ |
| EMPsurvEngage_9 | 1 | 1.00 | 76.64 | 15.54 | 10.00 | 68.00 | 79.00 | 88.00 | 100.00 | ▁▁▃▇▇ |
| EMPsurvEngagement | 1 | 1.00 | 81.18 | 10.02 | 39.00 | 75.00 | 83.00 | 89.00 | 99.00 | ▁▁▃▇▆ |
| EMPorgIntegrity1 | 1 | 1.00 | 69.99 | 14.33 | 18.00 | 61.00 | 71.00 | 80.00 | 100.00 | ▁▂▅▇▃ |
| EMPorgIntegrity2 | 1 | 1.00 | 85.74 | 10.94 | 35.00 | 80.00 | 88.00 | 94.00 | 100.00 | ▁▁▂▆▇ |
| EMPorgIntegrity3 | 1 | 1.00 | 88.73 | 10.31 | 35.00 | 83.00 | 91.00 | 96.00 | 100.00 | ▁▁▁▃▇ |
| EMPorgIntegrity4 | 1 | 1.00 | 84.91 | 10.88 | 27.00 | 80.00 | 86.00 | 92.00 | 100.00 | ▁▁▁▆▇ |
| EMPorgIntegrity5 | 1 | 1.00 | 470.11 | 269.76 | 1.00 | 237.50 | 470.00 | 703.50 | 936.00 | ▇▇▇▇▇ |
| EmpSurvOrgIntegrity | 1 | 1.00 | 159.89 | 54.53 | 54.00 | 113.10 | 164.60 | 207.60 | 258.20 | ▅▇▇▇▇ |
| EMPsurvSUP1 | 1 | 1.00 | 82.96 | 10.65 | 33.00 | 77.00 | 84.00 | 91.00 | 100.00 | ▁▁▂▇▇ |
| EMPsurvSUP2 | 1 | 1.00 | 85.24 | 10.99 | 30.00 | 79.00 | 87.00 | 93.00 | 100.00 | ▁▁▂▆▇ |
| EMPsurvSUP3 | 1 | 1.00 | 79.89 | 12.72 | 34.00 | 73.00 | 81.00 | 89.00 | 100.00 | ▁▂▃▇▆ |
| EMPsurvSUP4 | 1 | 1.00 | 81.35 | 12.13 | 27.00 | 73.00 | 82.00 | 91.00 | 100.00 | ▁▁▃▇▇ |
| EmpSurvSupervisor | 1 | 1.00 | 82.36 | 10.07 | 35.75 | 76.50 | 83.50 | 89.75 | 100.00 | ▁▁▂▇▆ |
Variables of interest
BAME: Percentage of the team comprised of Black, Asian, or Minority Ethnic employees.
Function: Function 1 = Sales staff (customer-facing roles) or 2 = Professional Service (non-customer-facing roles).
The data set contains both variables of interest as numbers.
The “BAME” variable is numeric, while the “Function” variable is categorical and needs to be transformed into a factor for analysis in R.
Data preparation
- Change the variable “Function” to categorical by creating a new variable named “profession” with two levels “Sales Staff” and “Professional Service”.
Code
# Create a new variable named "profession" with two levels "Sales Staff" and "Professional Service"
# Drop "NA" levels as they are not meaningful for the analysis
diversity <- diversity|>
mutate(profession = factor(Function,
levels = c(1:2),
labels = c("Sales Staff", "Professional Service")))|>
filter(profession != "NA")|>
droplevels()Summary statistics
See Table 1 for Measures of Center
Code
diversity|>
group_by(profession)|>
summarise(mean=mean(BAME, na.rm = TRUE),
median=median(BAME, na.rm = TRUE),
n= sum(!is.na(BAME)))|>
kable(col.names = c("Profession", "Mean", "Median", "Sum"), align = "cccc")| Profession | Mean | Median | Sum |
|---|---|---|---|
| Sales Staff | 0.0968317 | 0.05 | 404 |
| Professional Service | 0.1438596 | 0.10 | 342 |
- 404 teams within the “Sales Staff” profession and 342 teams within “Professional Service” profession reported the percentages of BAME.
Note
Note the difference between the mean and median of the percentage of BAME for each profession category.
What is the distribution of BAME employees for all teams and professionals across organization?
Code
# Custom label function
percent_label_1 <- function(x) {
paste0(100*x, "%")
}
ggplot(diversity, aes(x=BAME))+
geom_bar()+
scale_x_binned(labels = percent_label_1)+
theme_minimal(base_size = 12)+
theme(legend.position = "none")+
labs(title = "The most frequent values (around 300 of teams) fall into the range \nbetween 0 - 5%. As the level of percentage increases \nthe frequency decreases.",
subtitle = "Distribution of BAME employees",
x= "BAME employees",
y= "Count")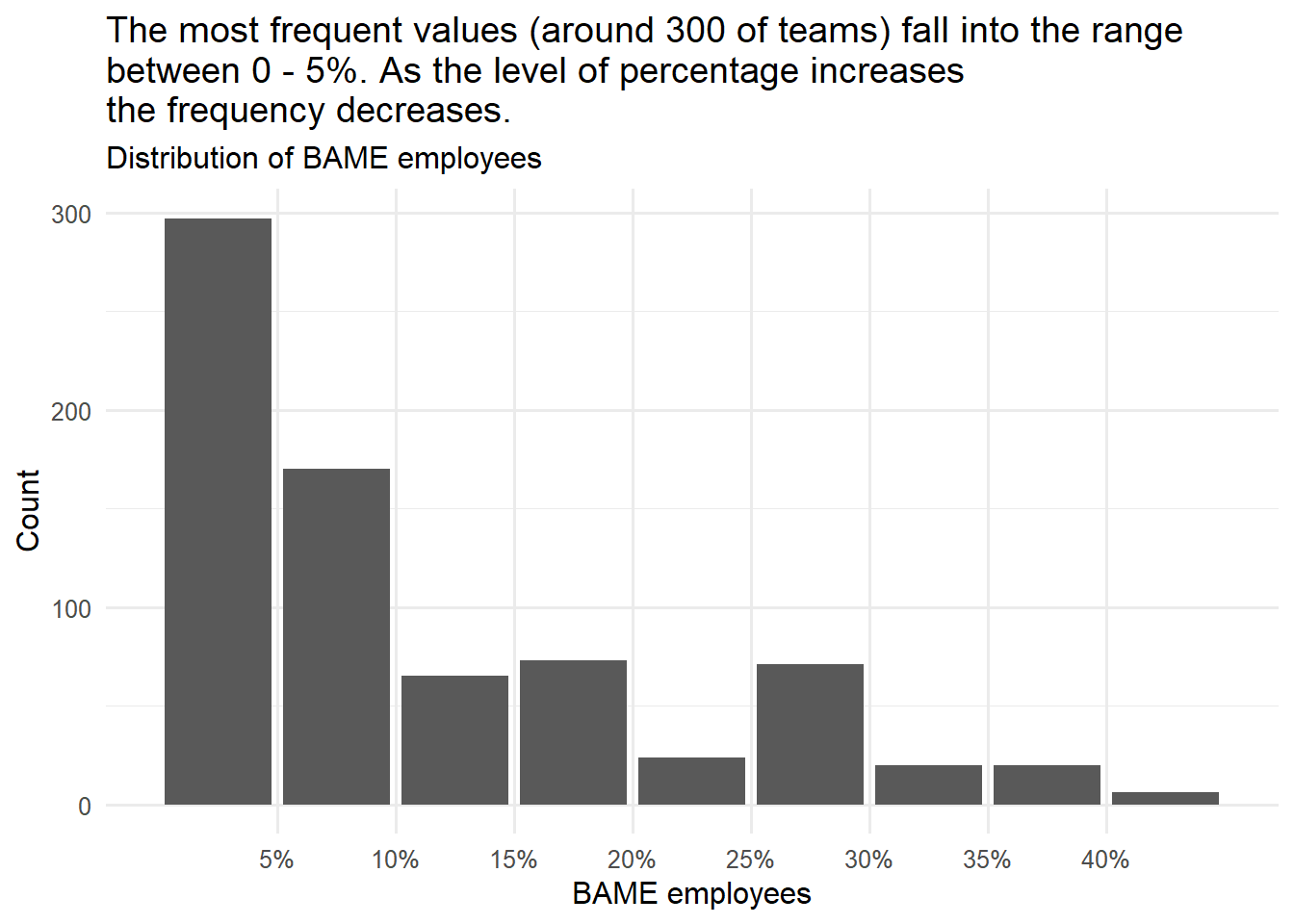
Note
The distribution has a long tail on the right side, and we can say that it is skewed to the right. When the data is skewed, the median is a better measure of the central tendency.
What is the distribution of BAME employees within the two professions?
Code
# Custom label function
percent_label_1 <- function(y) {
paste0(100*y, "%")
}
ggplot(diversity, aes(x=profession, y=BAME, color=profession))+
geom_violin()+
geom_boxplot(width=0.1, color="black", alpha=0.2)+
theme_minimal(base_size = 12)+
scale_color_manual(values = c("Sales Staff"= "#33645FFF", "Professional Service" = "#9D1B1FFF" ))+
theme(legend.position = "none")+
scale_y_continuous(labels = percent_label_1)+
labs( title = "There is greater BAME distribution in the Professional Service \nprofession compared with the Sales profession.",
subtitle = "BAME percentage by Profession",
x= NULL,
y= "BAME percentage")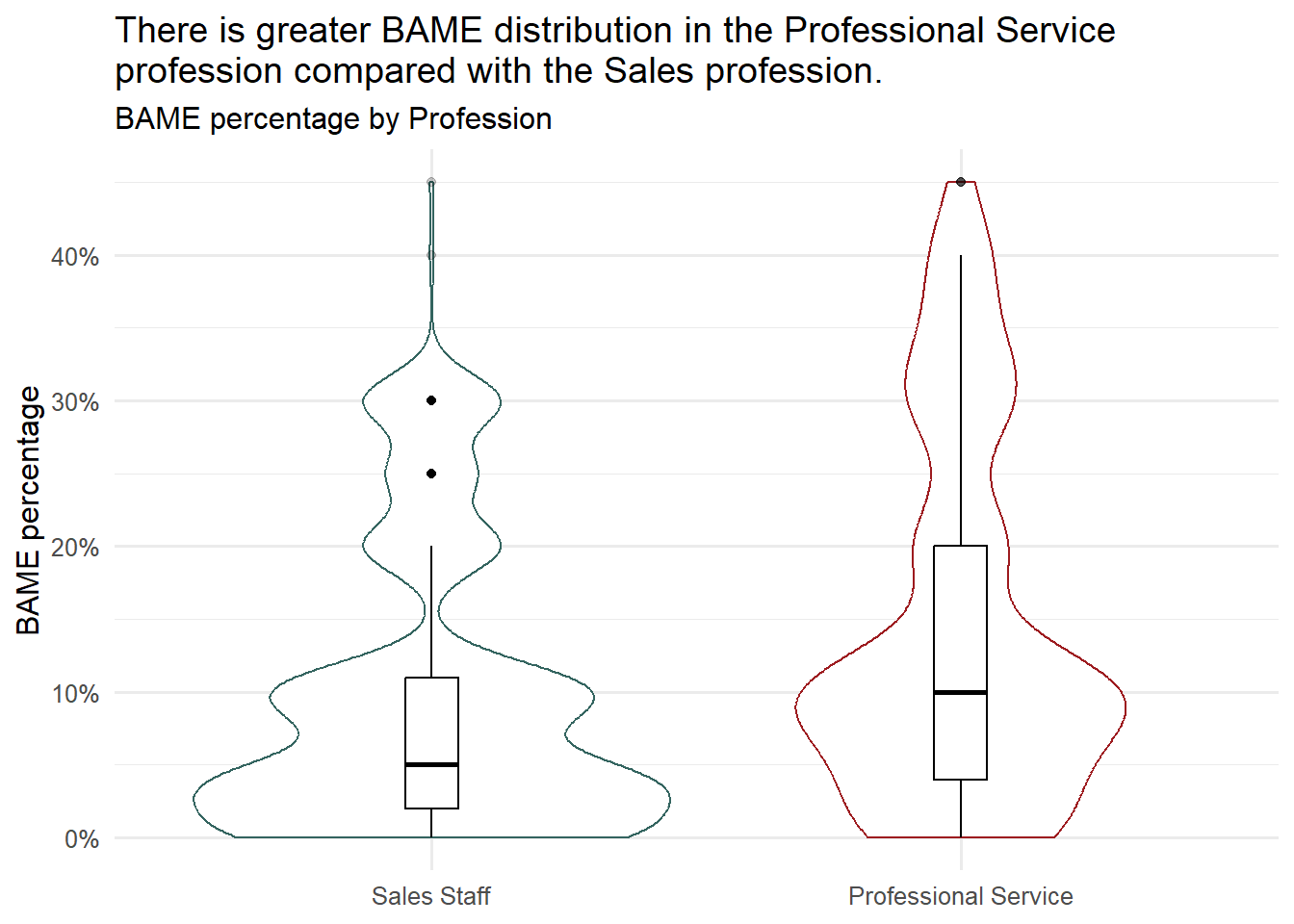
The box plot1 for the “Professional Service” profession has a longer length than the box plot for “Sales Staff”. This indicates that the data is more dispersed and there is greater diversity within the “Professional Service” profession.
Important
Note the potential outliers that may need further investigation. What is different in those teams where the percentage of BAME employees has extreme values?
Code
# Custom label function
percent_label <- function(x) {
paste0(100*x, "%")
}
ggplot(diversity, aes(x=BAME, fill=profession))+
geom_density(alpha = 0.5)+
labs(title = "BAME employees are significantly underrepresented in Sales Staff \ncompared to Professional Service teams.",
subtitle= "BAME distribution by Profession",
x = "BAME percentage",
y = "Density",
fill = "Profession")+
theme_minimal(base_size = 12)+
theme(panel.grid.minor = element_blank(),
axis.text.y = element_blank())+
scale_fill_manual(values = c("Sales Staff"= "#33645FFF", "Professional Service" = "#9D1B1FFF" ))+
scale_x_continuous(labels = percent_label)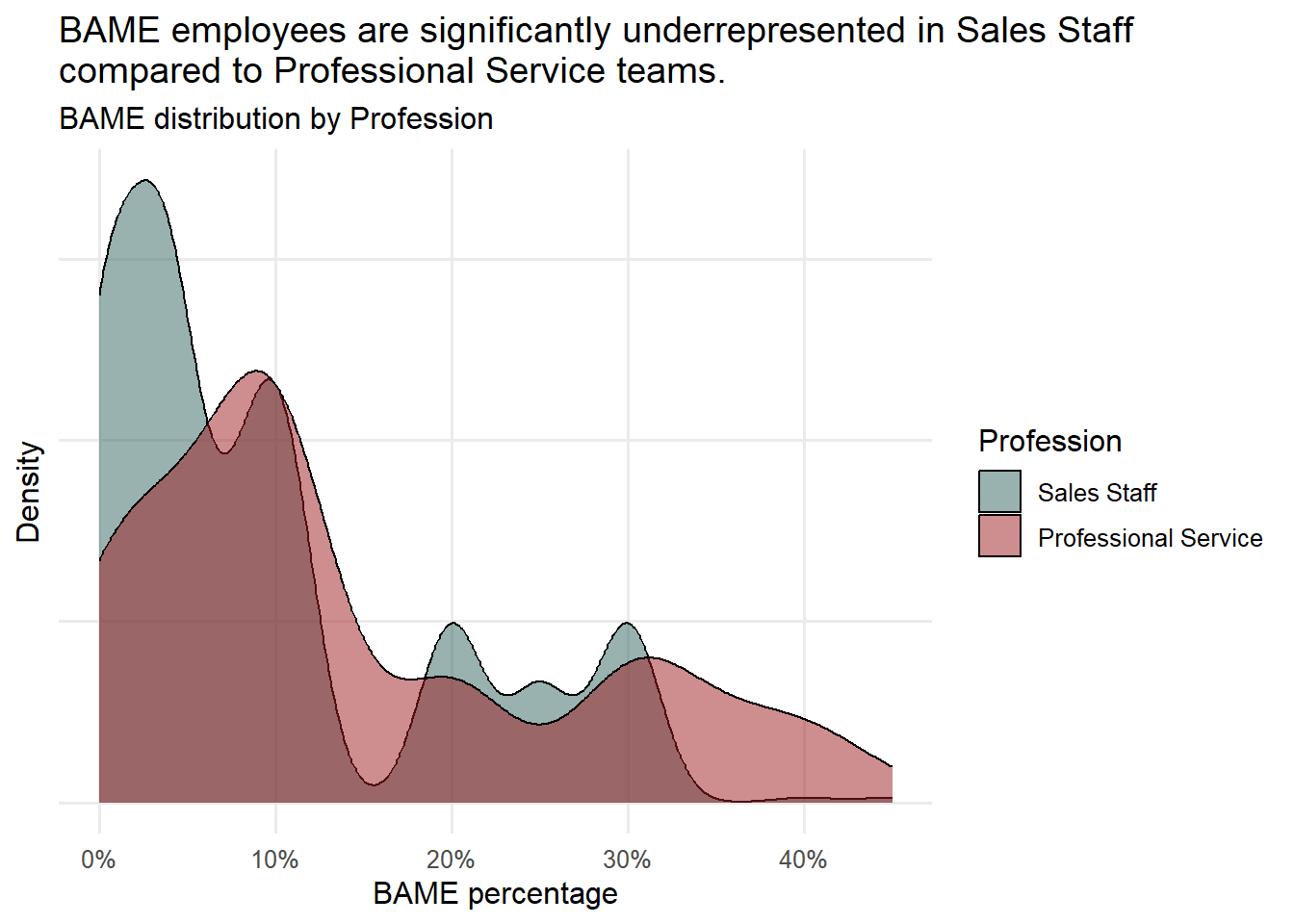
How does the distribution of BAME employees vary across different professions? (I)
- BAME employees are distributed differently across the two professions. There are more “Sales Staff” teams with a lower percentage of BAME employees, while “Professional Service” teams have a more even distribution.
- It’s essential to note that these findings are based on summary statistics and visual examinations, which may not be highly precise.
- To gain more confidence in comparing BAME representation between the two professions and to deepen our understanding of the organization’s ethnicity dynamics, we will conduct an Independent Samples t-Test.
Independent Samples t-Test
Levene’s Test for Equality of Variances
One of the requirements for the independent Samples t-test is the homogeneity of variances (i.e., variances approximately equal across groups).
However, if this requirement is violated and the sample sizes for each group differ, we can calculate t-test statistics. The independent samples t-test output also includes an approximate t-statistic, which doesn’t assume equal variances across populations. The Welch t-test statistic can be employed when equal variances between populations cannot be assumed.
The hypotheses
- H0: The population variances of “Sales Staff” and “Professional Service” are equal.
- H1: The population variances of “Sales Staff” and “Professional Service” are not equal.
leveneTest(diversity$BAME, group = diversity$profession, center=mean)Levene's Test for Homogeneity of Variance (center = mean)
Df F value Pr(>F)
group 1 35.396 4.141e-09 ***
744
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1The p-value is 4.141e-09, which is less than 0.05. This indicates very strong evidence against the null hypothesis, leading us to reject the null hypothesis of Levene’s Test.
This suggests that the variances of the two groups are not equal, meaning the assumption of homogeneity of variances is violated.
Independent Samples t-Test
- We want to determine if there is a statistically significant difference between the mean percentages of BAME employees in the “Sales Staff” and “Professional Service” professions within this organization.
- To achieve this, we can employ an Independent Samples t-Test to compare the means of BAME percentages for “Sales Staff” and “Professional Service.”
The hypotheses
- H0: The difference of the means is equal to 0
- H1: The difference of the means is not equal to 0.
t.test(diversity$BAME ~ diversity$profession, var.equal = TRUE)
Two Sample t-test
data: diversity$BAME by diversity$profession
t = -5.7695, df = 744, p-value = 1.166e-08
alternative hypothesis: true difference in means between group Sales Staff and group Professional Service is not equal to 0
95 percent confidence interval:
-0.06302979 -0.03102614
sample estimates:
mean in group Sales Staff mean in group Professional Service
0.09683168 0.14385965 t.test(diversity$BAME ~ diversity$profession, var.equal = FALSE)
Welch Two Sample t-test
data: diversity$BAME by diversity$profession
t = -5.6553, df = 640.61, p-value = 2.345e-08
alternative hypothesis: true difference in means between group Sales Staff and group Professional Service is not equal to 0
95 percent confidence interval:
-0.06335727 -0.03069866
sample estimates:
mean in group Sales Staff mean in group Professional Service
0.09683168 0.14385965 - The result of Levene’s Test suggests that we should consider using the Welch Two Sample t-test because the variances of the two groups are not equal.
- The p-value is 2.345e-08 for the t-test for unequal variances, which is less than 0.001. Therefore, we can conclude that there is a significant difference in the mean percentage of BAME employees between the two functions.
How does the distribution of BAME employees vary across different professions? (II)
- When comparing the “Sales Staff” and “Professional Service” functions, it becomes evident that the mean proportion of BAME staff is significantly lower in “Sales Staff” than in “Professional Service.”
- Specifically, the average proportion of BAME staff in teams within the “Sales Staff” function is 9.7%, while in “Professional Service” teams, it stands at 14.39%.
- A more in-depth analysis reveals that the likelihood of this difference occurring by chance alone is less than 1 in 1,000, suggesting that there is a significant issue within the “Sales Staff” function that requires attention in the organization.
Conclusion
Analyzing BAME distribution across professional functions
Summary statistics and graphical visualization offer a concise overview of the distribution of BAME employees in the two professions. It’s evident that more “Sales Staff” teams have a lower percentage of BAME employees, while “Professional Service” teams exhibit a more even distribution.
The results of the independent samples t-test, with a p-value close to 0, confirm a significant difference in the mean percentage of BAME employees between the two functions. This implies that there is an issue that needs attention within the “Sales Staff” function in the organization.
Recommendation
- According to our analysis, the organization faces challenges in BAME representation across professions, particularly in the “Sales Staff”.
- Further research should be conducted to identify the factors influencing or associated with the diversity disparities between these two teams.
Footnotes
- ↩︎
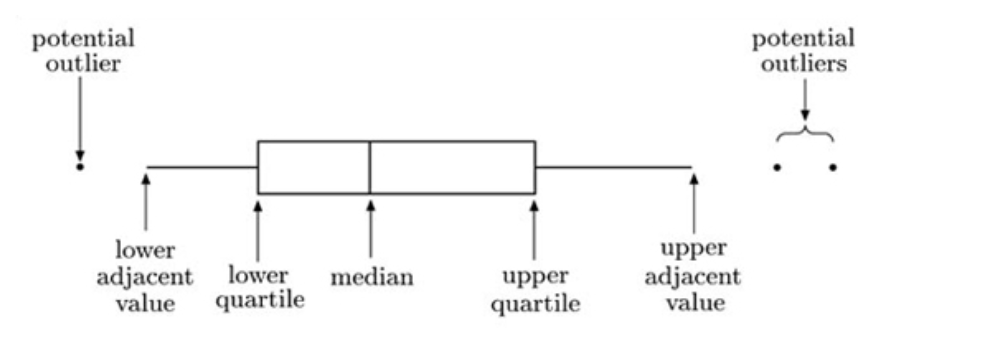
A typical boxplot. The ends of the box mark the quartiles, and the vertical line through the box is located at the median. The whiskers of a boxplot extend to values known as adjacent values. These are the values in the data that are furthest away from the median on either side of the box, but are still within a distance of 1.5 times the interquartile range from the nearest end of the box (that is, the nearer quartile). In many cases the whiskers actually extend right out to the most extreme values in the data set. However, in other cases they do not. Any values in the data set that are more extreme than the adjacent values are plotted as separate points on the boxplot. This identifies them as potential outliers that may need further investigation.